被动扫描中http流量清洗
0x00 写在前面
几个月前写的被动扫描工具rcefuzzer的实际使用效果挺好的,除了被污染的流量贼它娘的多以外,需要清洗掉无意义的流量。
0x01 核心问题
减少请求数量的核心问题是:
如何确定流量是否是重复的?
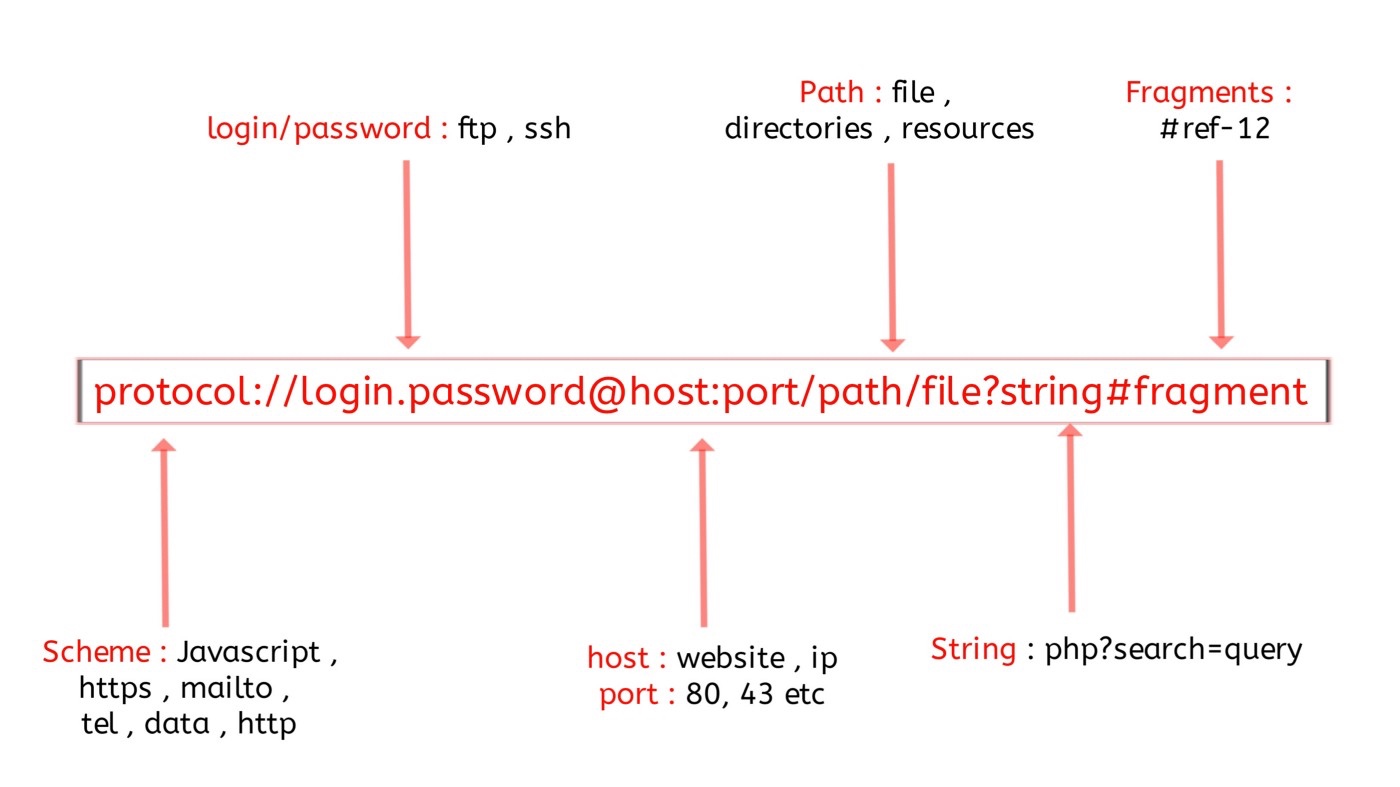
一个完整的标准链接包含了协议,凭证,目的地址,目标端口,路由,参数,描点这7部分,凭证和描点,其中凭据和描点都属于浏览器层面用户操作体验的问题,不用考虑。那么将其他五个部分加上不同的请求方法组成一个向量就是:
请求方法:协议:域名:端口:URL路径:参数名称排序合集
请求方法,协议,域名,端口这四个的变化比较小,基本上是固定的,也不用考虑怎么考虑。
0x02 路由处理
URL路径的花样会比较多,去除资源文件的不多说,这里主要考虑其他情况,比如
A:/path1/path2
B:///path1////path2
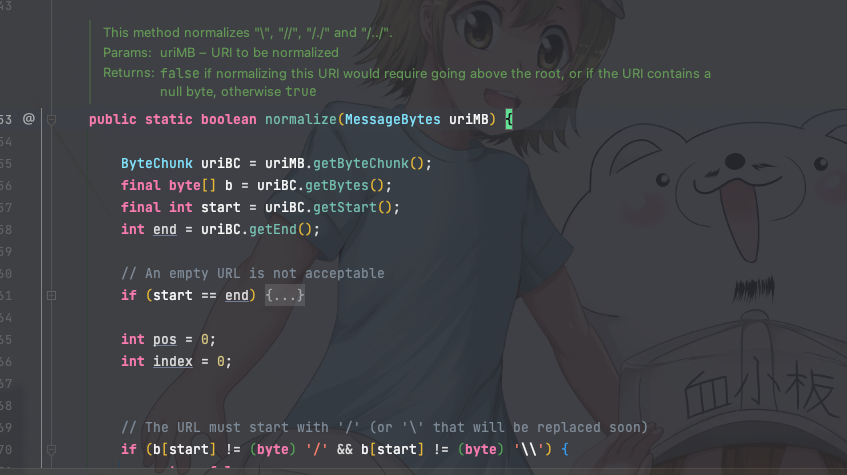
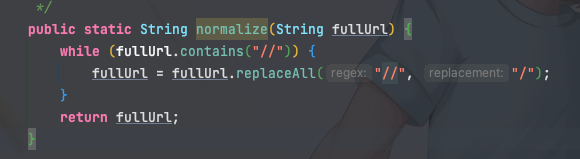
这里在处理的时候比较好奇中间件是怎么判断两个路由等效的,于是翻了以下代码,在org.apache.catalina.connector.CoyoteAdapter#normalize中可以看到代码对\,//,/./,/../等字符串进行了处理,路径标准化后再去做servlet调度。
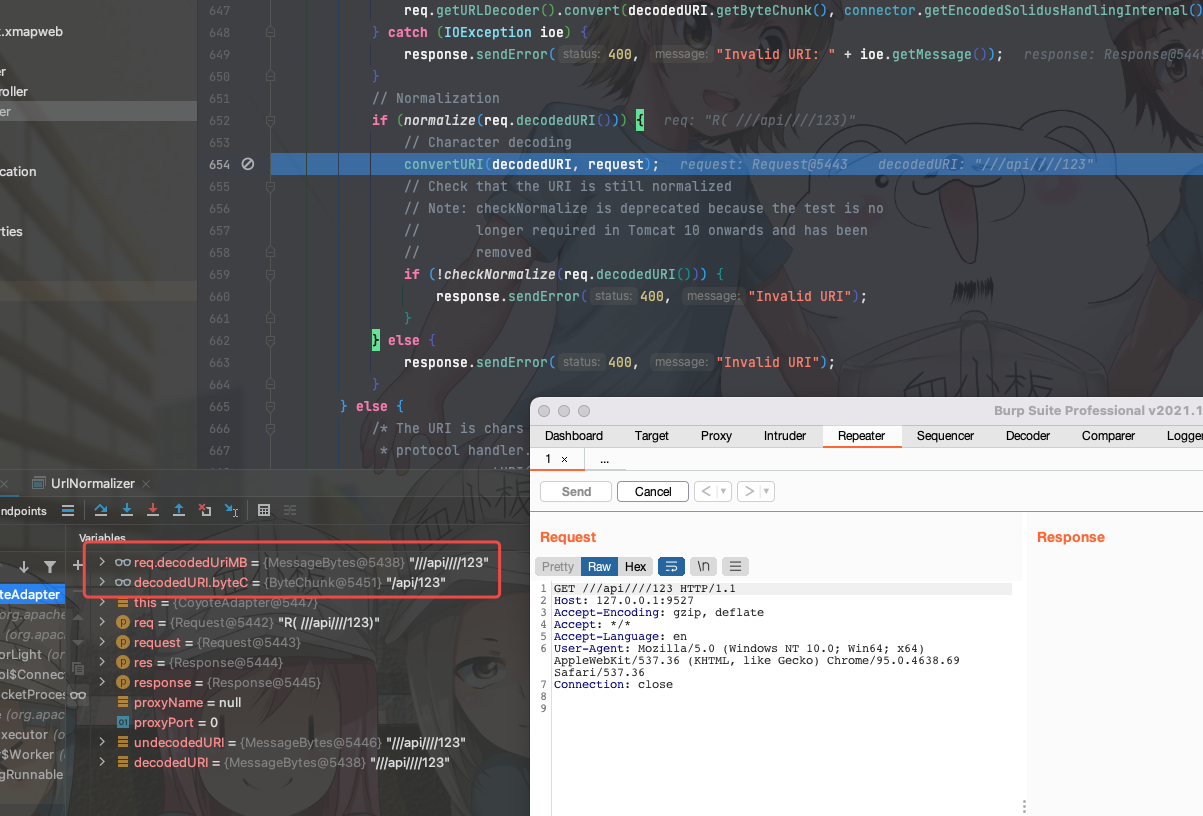
对于做流量清洗来说,只需要关注:
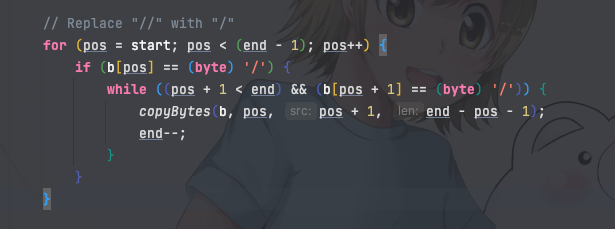
这个实现读起来没那么友好,那么可以改写为:
再比如:
A:/news/1
B:/news/2
C:/news/1/read
D:/news/2/edit
很明显的是restfull风格或者伪静态的写法,AB属于同一个路由,BC不同,后端的写法可能是:
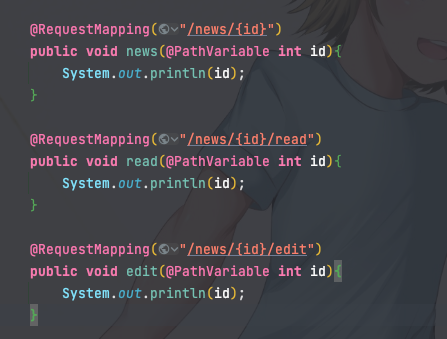
处理思路也比较清楚,路径标准化后再切割一下,尝试转换成不通的整数,相同的视作同一路由即可。
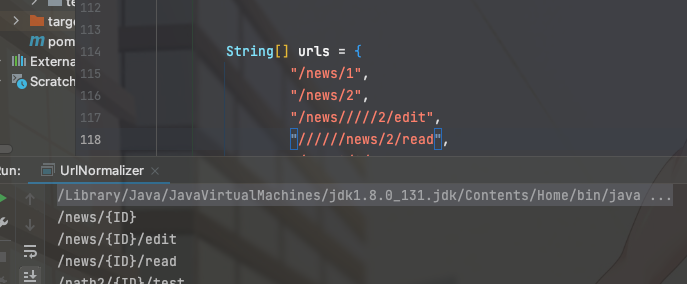
除了数字这种还经常遇到用hash或者uuid的,处理方式差不多,判断依据均已标准化后的路由为准。
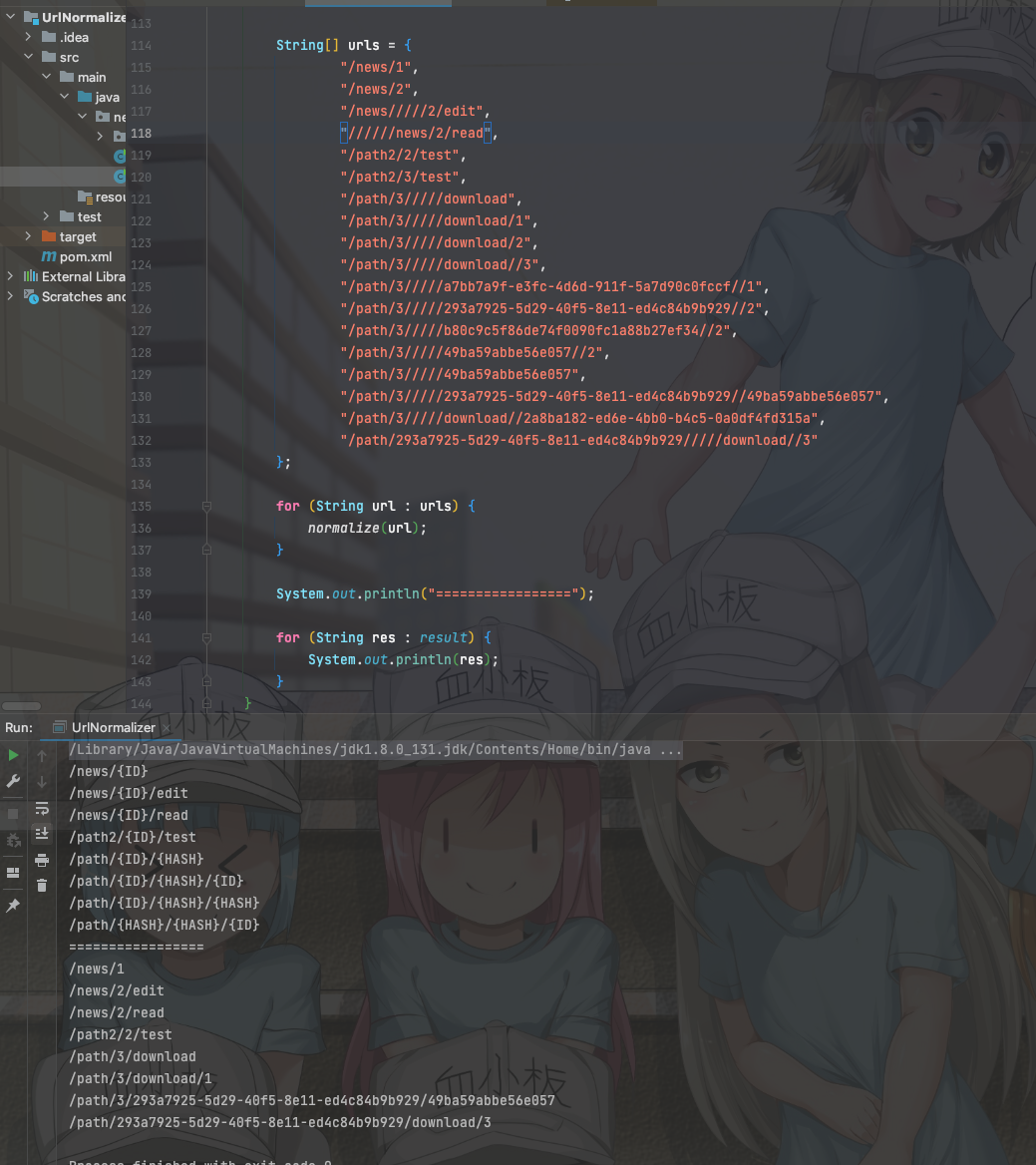
0x03 参数处理
已经考虑到的后端写法如:
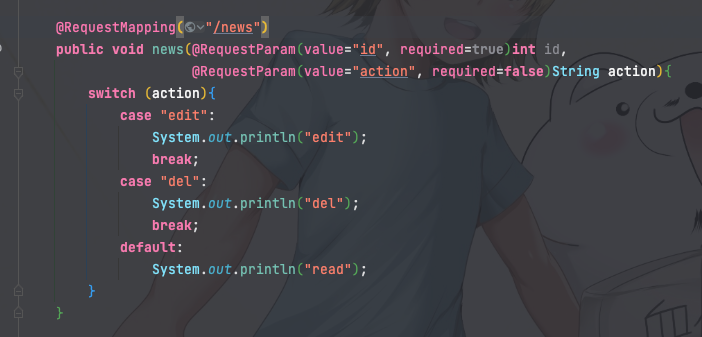
对应的URL如下:
A:/news?id=2
B:/news?action=edit&id=2
C:/news?action=del&id=2
D:/news?id=2&action=del
从相邻的来看,AB的参数不同,扫完A肯定得接着扫,但B扫完再扫C实际意义不大。CD的参数顺序不通,但本质上D和BC也是一样的。综合下来处理的思路是获取所有参数名排序后组成一个向量,作为判断流量是否重复的依据。也就是说,ABCD实际上只需要扫描AB即可。
0x04 写在最后
orz... 做的时候感觉蛮多东西可以玩的,写出来就感觉索然无味,被自己菜哭ಥ_ಥ。
